をローカルで実行:方法と応答速度をすべて公開.png)
Hugging Face上の生成AIモデルをダウンロードし、ローカル上で使えるようにする方法を紹介します。
Hugging FaceのTransformersライブラリを使います。Transformersは、自然言語処理(NLP)と呼ばれる技術を簡単に使えるようにするための無料のプログラムです。
自然言語処理(Natural Language Processing)とは、コンピュータに人間の言葉を理解させる技術のことです。最後に使用したパソコンの性能と、どれほどのメモリを使用したかなどもお伝えします。
ご自身のローカル上で動かせるか悩まれたら、参考にしてくださいね。
Pythonのインストール
下記についてはあらかじめインストールしたという前提でお伝えしていきます。
- Python 3 (すでにインストールされていることを確認してください)
- テキストエディター(VSCodeなど)
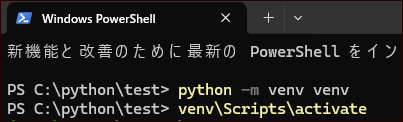
今回は仮想環境を使っていきます。
仮想環境の作成
プロジェクトを作成したい場所に、「test」という名前のフォルダを作ります。この場所で、コマンドプロンプトやWindows Power Shellを起動します。
次のコマンドを実行して仮想環境を作成します。
|
1 |
python -m venv venv |
仮想環境のアクティベーション
以下のコマンドを使用して、仮想環境をアクティベートします。
|
1 |
venv\Scripts\activate |
ライブラリのインストール
仮想空間上で、必要なライブラリをインストールします。
|
1 |
pip install transformers torch accelerate |
![]()
生成AIモデルのダウンロード
testフォルダ内にtest.pyを作ります。今回は下記の生成AIモデルを使います。
|
1 |
https://huggingface.co/google/gemma-2-2b-jpn-it |
下記のようにコードをいれます。
【test.py】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
from huggingface_hub import login login(token="hf_token") from transformers import AutoTokenizer, AutoModelForCausalLM import torch model_name = "google/gemma-2-2b-jpn-it" # トークナイザーのダウンロード tokenizer = AutoTokenizer.from_pretrained(model_name) # モデルのダウンロード model = AutoModelForCausalLM.from_pretrained( model_name, device_map="auto", torch_dtype=torch.bfloat16 ) # モデルとトークナイザーをローカルに保存 tokenizer.save_pretrained("./local_gemma_model") model.save_pretrained("./local_gemma_model") |
次に、HuggingFace上でトークンを取得します。Settings/Access Tokens/Create new tokenボタンをクリックします。トークンのパーミッションは下記のようにします。
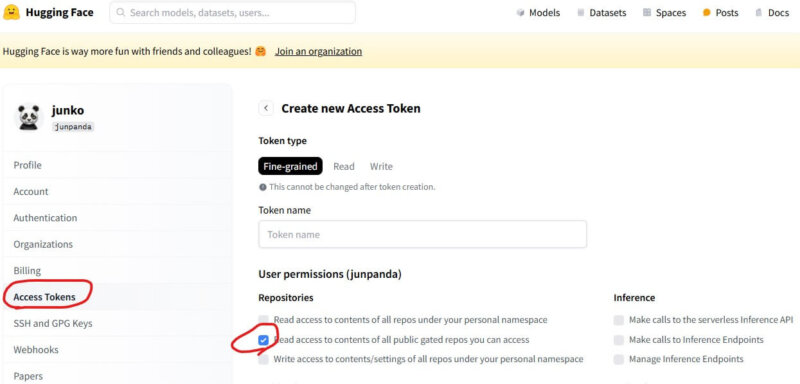
作成したトークンをコピーします。test.pyのトークンをいれるべきところに貼り付けます。
下記のコマンドを実行すると、test.pyファイルが実行され、モデルをダウンロードできます。
|
1 |
python test.py |
なおしばらく時間がかかるので放置します。ダウンロード後、testフォルダ内に「local_gemma_model」フォルダができます。フォルダ内にはモデルファイルが入っています。容量は4.9GBとなりました。

モデルを使ってテキスト生成を実行
次にダウンロードしたモデルを実行してみます。testフォルダ内にtest2.pyを作成し、下記のようなコードをいれます。
「マシーンラーニングについての詩を書いてください。」はお好きなようにかえてくださいね。
【test2.py】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
from transformers import AutoTokenizer, AutoModelForCausalLM import torch # ローカルに保存したモデルとトークナイザーを読み込む tokenizer = AutoTokenizer.from_pretrained("./local_gemma_model") # 下記はCPUを使用する場合。 # GPUの場合は、device_map="auto", torch_dtype=torch.bfloat16 とします。 model = AutoModelForCausalLM.from_pretrained( "./local_gemma_model", device_map="cpu", torch_dtype=torch.float32 ) # テキスト生成の例 messages = [ {"role": "user", "content": "マシーンラーニングについての詩を書いてください。"} ] inputs = tokenizer.apply_chat_template(messages, return_tensors="pt", add_generation_prompt=True).to(model.device) outputs = model.generate(inputs, max_new_tokens=256) generated_text = tokenizer.batch_decode(outputs[:, inputs.shape[1]:], skip_special_tokens=True)[0] print(generated_text.strip()) |
下記のコマンドを実行すると、test2.pyファイルが実行されます。
|
1 |
python test2.py |
実行結果は下記のようになりました。
![]()
パソコンの性能と処理結果
なお、今回のテストに使ったわたしの環境は下記のとおりです。
- CPU: Intel Core i7-13700F (passmarkのスコアは38902)
- 物理メモリの合計: 32 GB
わたしはいくつかPCを所有しておりますが、通常使用しているPCではやはり性能がイマイチでした。そのため、上記の環境にしてみました。
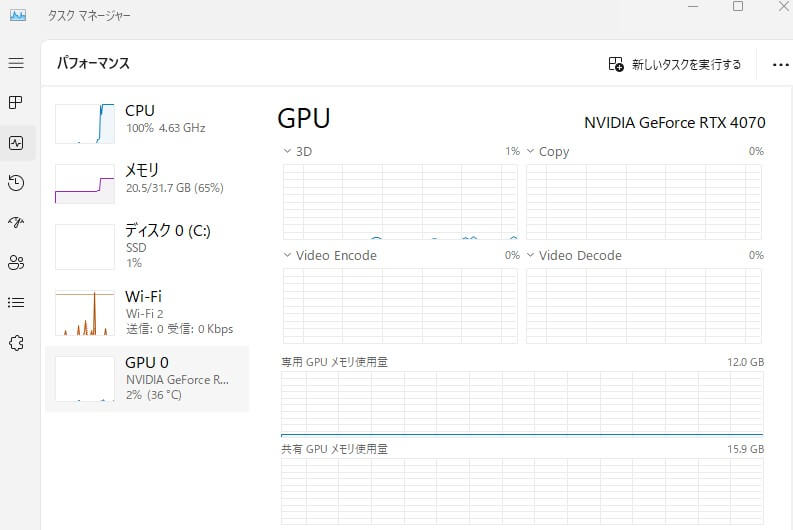
今回のテストでは215文字のテキストを生成した際、60秒ほどかかりました。使ったのは、約20億(2B)のパラメータを持つ生成AIモデルです。稼働中(test2.py実行中)は、メモリは20GBぐらい使われていました。16GBの環境で行った場合には、動作しない可能性があります。
さいごに
今回は通常より性能は良いものの、CPU環境を使用しています。正直、回答を得るのに60秒もかかるのは、現実的ではありません。
「あまり使えないことが分かった」という実験結果でした。
ローカル上でテキスト生成用のAIモデル(LLM)を動かすのであれば、Ollama(オラマ)というツールが便利です。Ollamaなら、設定もラクになりますし、回答にも時間がかかりません。
Ollamaについては、下記のYoutube動画で詳しくご紹介しているので、参考にしてくださいね。

のインストールとコマンドの使い方-120x68.png)