WordPressで作成したブログやウェブサイトのコンテンツを生成AIの学習に使われたくない場合は、robots.txtの編集が効果的です。
以下、方法を説明しますね。
「生成AIにデータを使われたくない」と思っていたら、参考にしてください。
robots.txtとは?
robots.txtはウェブサーバーに設置されるテキストファイルです。
検索エンジンのクローラー(ロボット)がサイトのどの部分をクロールしてよいかを指示します。このファイルにルールを記述することで、特定のクローラーのアクセスを拒否したり、サイトの特定の部分へのアクセスを制限することが可能です。
robots.txtの編集方法
主要な生成AIサービスをブロックするには、robots.txtに下記のように記述します。
【robots.txt】
|
1 2 3 4 5 6 7 8 9 10 11 |
# ChatGPTクローラーをブロック User-agent: GPTBot Disallow: / # ClaudeBotクローラーをブロック User-agent: ClaudeBot Disallow: / # Google-Extendedクローラーをブロック User-agent: Google-Extended Disallow: / |
各種サービスごとに設定しなければいけないのはちょっと面倒ですが、他にもブロックしたいサービスがあれば、追加してください。
なお編集したrobots.txtファイルは、FTP等を使ってワードプレスのルートドメインに配置します。
直接サーバーを編集するのが不安という場合には、プラグインを利用することもできます。[block ai crawler]などの検索語句を使ってみてください。
robotx.txtへの書き方について
なおサービスによって、robots.txtへの書き方を公表しているところと、していないところがあります。ChatGPTでは、こちらのページで、robots.txtの書き方を説明してくれています。
Google 検索でのサイトの登録と掲載順位に Google-Extended が影響することはありません。
さすがGoogleさん、不安なユーザーの気持ちを読み取ってくれているかのような説明です。
robots.txtに書いた結果
上記のように設定した場合、生成AIのほうでは、ブログ記事などを読み取れなくなります。本サイトにもご紹介したような形でrobots.txtを設定しました。
その上で、ChatGPTに本ブログ記事の要約をお願いしました。すると、次のような回答が返ってきました。
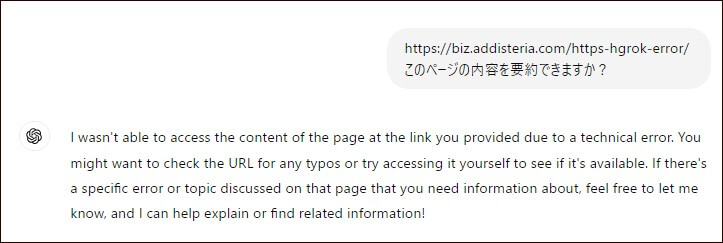
I wasn’t able to access the content of the page at the link you provided due to a technical error.(技術的なエラーのため、ご提供いただいたリンク先のページの内容にアクセスできませんでした。)
しっかりとChatGPTのアクセスがブロックされているようです。
ご留意点:robots.txtは絶対ではない
robots.txtによる対策は、残念ながら「絶対」ではありません。
robots.txtは「お願い」であり、強制力はありません。現在公式サイトでrobots.txtについて説明しているサービスはこの指示に従うかと思いますが、そうではないサービスもあるでしょう。
実際、少し前にPerplexitiyというサービスがrobots.txtを無視してウェブサイトから情報を抜き出しているとニュースになっていました。これに対し、Perplexitiy側では否定していますが、ただ、何とも微妙な展開になっています。。

さいごに
今回はWordpressコンテンツがAI学習に使われないようにするための方法をご紹介しました。
現行の著作権法では、コンテンツがAI学習に使われるのを防ぎきれません。そのため、今回ご紹介した方法以外でも技術的に「学習ブロック」を行う方法が出てくれば、多くのコンテンツ作成者は、その方法を使うでしょう。
コンテンツ作成者としては、当然の流れだと思います。
ただ、学習コンテンツが減ってしまうと、その分後発の生成AIサービス開発者に不利になります。またコンテンツが有料化したりすれば、資金のない会社では良いサービスを提供できなくなります。
そうなると、既存の資金力のある企業が生成AI市場を独占する状態になりかねません。
このあたり、なかなか難しい問題ですよね。引き続き動向を見守りつつ、役立つ情報をお届けしていきたいと思います。